摘要:本文主要介绍如何详细解读GaussDB(DWS)产生的分布式执行计划,从计划中发现性能调优点。前言
执行计划(又称解释计划)是数据库执行SQL语句的具体步骤,例如通过索引还是全表扫描访问表中的数据,连接查询的实现方式和连接的顺序等。如果 SQL 语句性能不够理想,我们首先应该查看它的执行计划。本文主要介绍如何详细解读GaussDB(DWS)产生的分布式执行计划,从计划中发现性能调优点。
1、执行算子介绍
要读懂执行计划,首先要知道数据库执行算子的概念:

下面重点介绍下基于sharing nothing的分布式计划中最重要的一类算子——STREAM算子
三种类型的stream算子
1)Gather Stream(N:1) – 每个源结点都将其数据发送给目标结点

2)Redistribute Stream(N:N) – 每个源节点将其数据根据连接条件计算Hash值,根据重新计算的Hash值进行分布,发给对应的目标节点

3)Broadcast Stream(1:N) – 由一个源节点将其数据发给N个目标节点

其中1)主要用于CN与DN间的数据交换,2)与3)主要用于DN间的数据交换
2、EXPLAIN用法
SQL执行计划是一个节点数,显示执一条SQL语句执行时的详细步骤。每一个步骤是一个数据库运算符,也叫作一个执行算子。使用explain命令可以查看优化器为每个查询生成的具体执行计划。
1) EXPLAIN的语法

其中,option中COSTS与NODES的默认值为ON,其他参数默认为OFF。
说明:
a) EXPLAIN + QUERY并不会真正执行,只会将计划打印出来,指定option中的ANALYZE可以进行实际执行
b) PERFORMANCE 选项默认会将所有的选项置为ON,即显示所有的执行信息。
c) CPU/BUFFER/DETAIL 选项依赖于ANALYZE,只有ANALYZE置为ON的时候,才能使用这几个选项。
d) DETAIL选项用来控制输出,DETAIL 置为ON时,会显示各个DN上具体的执行信息;DATAIL 置为OFF时,显示所有DN的汇总信息,即最大最小值信息。

2) EXPLAIN显示格式
GaussDB中提供了两种显示格式(normal/pretty),通过设置参数explain_perf_mode进行控制。其中,normal格式为默认的显示格式。
normal格式如下:

pretty格式如下:

改进后的显示格式,层次清晰,计划包含了plan node id,性能分析会更加简单直接。
使用之前可以使用show explain_perf_mode;来查看当前数据库使用的显示风格。
同时可以使用set explain_perf_mode=pretty/normal;来设置输出的格式。
3、示例计划解读(每个算子资源消耗、耗时等等)
1) 四中常见类型计划
建表语句:

a) FQS计划,完全下推,下发query

两表JOIN,且其连接条件为各表的分布列,在关闭stream算子的情况下,CN会直接将该语句发送至各DN执行,最后结果在CN汇总。
b) 非FQS计划,部分语句下推

两表JOIN,且连接条件中包含非分布列,此时在关闭stream算子的情况下,CN会将基表扫描语句下发至各DN,然后在CN上进行JOIN。
c) Stream计划,DN之间无数据交换

两表JOIN,且连接条件为各表的分布列,因此各DN无需数据交换。CN生成stream计划后,将除Gather Stream的计划下发给DN执行,在各个DN上进行基表 扫描,并进行哈希连接后,发送给CN。
d) Stream计划,DN之间存在数据交换

两表JOIN,且连接条件包含非分布列,在开启stream算子的情况下,会生成stream计划,其DN间存在数据交换。此时对于tt02表,会在各DN进行基表扫描,扫描后会通过Redistribute Stream算子,按照JOIN条件中的tt02.c1进行哈希计算后重新发送给各DN,然后在各DN上做JOIN,最后汇总到CN。
2) explain performance详解
a) 执行计划

"text-align: center">
显示对应执行算子节点的过滤条件
c) 内存使用

主要显示CN的最大内存用量、DN最大内存用量、各算子的最大内存用量、各算子预估内存用量、Stream线程的启动以及收发时间。
d) Targetlist Information

各个算子对应的输出目标列信息。
e) DN信息

各算子的执行时间、Buffer、CPU信息
f) 自定义信息

CN与DN之间的建连信息、DN与DN之间的建连信息。
g) 汇总信息

DN执行器开始时间,[min_node_name, max_node_name] : [min_time, max_time]DN执行器结束时间,[min_node_name, max_node_name] : [min_time, max_time]Remote query poll time:接收结果时用于poll等待的时间CN执行器开始、运行及结束时间网络流量,stream算子发送的数据量优化器执行期时间查询ID总执行时间
h) 执行时间介绍
每个算子的执行信息都包含三个部分:

其中:
dn_6001_6002/dn_6003_6004 表示具体执行的节点信息,括号中的信息是实际的执行信息actualtime=0.013..2290.971 表示实际的执行时间
第一个数字表示执行时进入当前算子到输出第一条数据所花费的时间
第二个数字为输出所有数据的总执行时间
注意:在整个计划中,除了叶子节点的执行时间是算子本身的执行时间,其余算子的执行时间均包含子节点的执行时间。

在该计划中,7号节点和9号节点为叶子节点,其余节点均为非叶子简介。1号节点时顶层节点,所以该节点的执行时间就可以作为整个查询的执行时间。
rows=2001550 表示当前算子输出数据为2001550行;loops=1 表示当前算子的只执行了一次,而对于分区表的扫描(7号节点)来说:

该层扫描算子的loops为7,对于分区表,每一个分区表的扫描就是一次完整的扫描操作,当切换到下一个分区的时候,又是一次新的查询操作,查询该表定义如下:

Inventory表有7个分区,所以就执行了7次表扫描操作,因此loops=7。
i) CPU信息介绍

每个算子执行的过程都有CPU信息,其中cyc代表的是CPU的周期数,ex cyc表示的是当前算子的周期数,不包含其子节点;inc cyc是包含子节点的周期数;ex row是当前算子输出的数据行数;ex c/r则是ex cyc/ex row得到的每条数据所用的平均周期数。
j) Buffer信息介绍

buffers显示缓冲区信息,包括共享块和临时块的读和写。
共享块包含表和索引,临时块在排序和物化中使用的磁盘块。上层节点显示出来的块数据包含了其所有子节点使用的块数。
Buffers涉及的参数有两种,分别为:shared和temp,及shared hit/read/dirtied/written以及temp read/write
Hit blocks:代表从磁盘里面读到的数据块数
Dirtied blocks:代表当前查询中被修改了的并且此前未被修改的数据块数
Written blocks:代表当前线程将shared bufer里被修改的数据写回到磁盘的块数
k) 执行内存

其中:
Peak Memory:5KB 表示当前算子实际执行时使用的峰值内存;
Estimate Memory:1024MB 表示预估的内存,为优化器给出的预估值。
l) 其他执行信息
(1)sort 算子,会显示排序信息

Sort Method代表排序的方法,包括quicksort(快排)和disksort(外排)。快排即内存够用时,所有的排序操作均在内存中完成,外排说明当前可用内存不足,需要下盘。
(2)hashjoin算子

Buckets:代表hash表中实际使用的桶的个数
Batches:代表hashjoin中实际分块的数量。如果Batches=1,则说明所有的数据全在内存中,没有下盘操作;反之则说明有下盘操作,Batches - 1代表临时文件的个数。
Memory Usage:就是hashjoin中内存的使用情况
(3)hashagg算子
如果发生数据下盘,会有File Num:512信息,显示临时文件的个数。
(4)stream算子

stream算子的会统计当前算子处理数据的字节数,其从子线程获取数据的时间(poll time)以及处理数据的时间(Deserialize Time)。
stream算子的子节点会统计发送端的时间信息,如下:

发送时间Send time,排队时间Wait Quota time, OS发送时间以及数据处理的时间。
3) explain 调优示例
一个查询语句要经过多个算子步骤才会输出最终的结果。由于个别算子耗时过长导致整体查询性能下降的情况比较常见。这些算子是整个查询的瓶颈算子。通用的优化手段是EXPLAIN ANALYZE/PERFORMANCE命令查看执行过程的瓶颈算子,然后进行针对性优化。
基表扫描时,对于点查或者范围扫描等过滤大量数据的查询,如果使用SeqScan全表扫描会比较耗时,可以在条件列上建立索引选择IndexScan进行索引扫描提升扫描效率。如下示例:

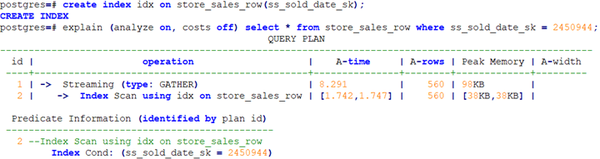
上述例子中,全表扫描返回3360条数据,过滤掉大量数据,在sssolddate_sk列上建立索引后,使用IndexScan扫描效率显著提高,从960毫秒提升到8毫秒。
结语:
在调优过程中,熟练使用explain并能分析各部分数据结果是非常重要的。本文中仅仅介绍了大多数字段的含义以及根据explain结果进行调优的一个小示例,还可以与plan hint结合使用找出执行的最佳路径,也可以定位倾斜程度等等。
免责声明:本站文章均来自网站采集或用户投稿,网站不提供任何软件下载或自行开发的软件! 如有用户或公司发现本站内容信息存在侵权行为,请邮件告知! 858582#qq.com
更新日志
- 小骆驼-《草原狼2(蓝光CD)》[原抓WAV+CUE]
- 群星《欢迎来到我身边 电影原声专辑》[320K/MP3][105.02MB]
- 群星《欢迎来到我身边 电影原声专辑》[FLAC/分轨][480.9MB]
- 雷婷《梦里蓝天HQⅡ》 2023头版限量编号低速原抓[WAV+CUE][463M]
- 群星《2024好听新歌42》AI调整音效【WAV分轨】
- 王思雨-《思念陪着鸿雁飞》WAV
- 王思雨《喜马拉雅HQ》头版限量编号[WAV+CUE]
- 李健《无时无刻》[WAV+CUE][590M]
- 陈奕迅《酝酿》[WAV分轨][502M]
- 卓依婷《化蝶》2CD[WAV+CUE][1.1G]
- 群星《吉他王(黑胶CD)》[WAV+CUE]
- 齐秦《穿乐(穿越)》[WAV+CUE]
- 发烧珍品《数位CD音响测试-动向效果(九)》【WAV+CUE】
- 邝美云《邝美云精装歌集》[DSF][1.6G]
- 吕方《爱一回伤一回》[WAV+CUE][454M]